Hugging Face Released Open LLM Leaderboard v2: New Benchmarks for Rigorous Language Model Evaluation
02/07/2024 09:46:58
Last week, Hugging Face released the Open LLM Leaderboard v2. This update addresses the shortcomings of the first version. The new leaderboard includes stricter benchmarks, improved evaluation methods, and a more balanced scoring system. These enhancements aim to give the AI community a clearer understanding of language model performance and encourage healthy competition.
Let’s take a look at what's new in the leaderboard.
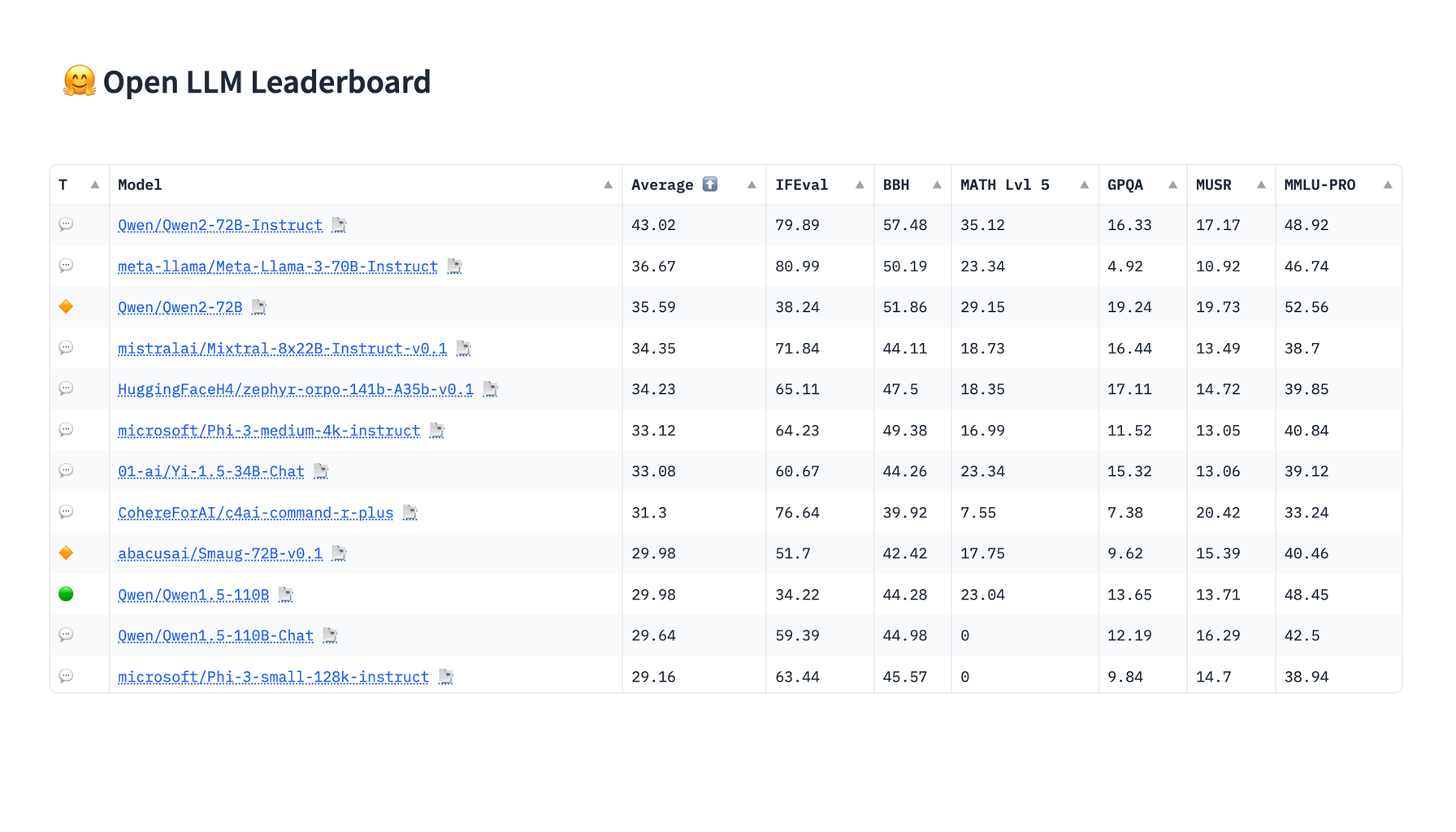
MMLU-Pro Correction: MMLU-Pro: Ten-Choice Questions Instead of Four
MMLU-Pro (Massive Multitask Language Understanding - Professional)
Overview: MMLU-Pro is designed to test professional-level knowledge and complex reasoning.
Key Features: This benchmark expands the original MMLU by incorporating more challenging tasks across various professional fields, including medicine, law, and engineering. The questions are now more complex, requiring advanced reasoning and problem-solving skills. Additionally, the number of answer choices has increased from four to ten, and trivial questions have been removed to enhance the benchmark's robustness and discrimination.
Benefits: This update makes the MMLU-Pro a more effective tool for evaluating language models, demanding greater reasoning abilities and expert review to ensure accuracy.
GPQA: A Highly Challenging Knowledge Dataset
GPQA (Graduate-Level Google-Proof Q&A Benchmark)
Overview: GPQA is designed for advanced question answering.
Key Features: This benchmark evaluates the capabilities of large language models in answering high-level, domain-specific questions in fields such as biology, physics, and chemistry. The multiple-choice questions are crafted to be highly challenging and cannot be easily answered through simple web searches. This ensures the questions test the depth of the model's understanding and reasoning.
Benefits: Developed by domain experts to ensure difficulty and factual accuracy, GPQA also includes gating mechanisms to prevent contamination, making it a rigorous tool for assessing the true capabilities of language models.
MuSR: Complex Multistep Reasoning
MuSR (Multistep Soft Reasoning)
Overview: MuSR focuses on testing multistep reasoning in natural language.
Key Features: This dataset is designed to evaluate the ability of large language models to handle complex, multi-step reasoning tasks. The tasks are presented in natural language narratives and are algorithmically generated using a neurosymbolic synthetic-to-natural generation algorithm. Scenarios include intricate problems like murder mysteries and team allocation optimizations, challenging the model's logical and inferential reasoning capabilities.
Benefits: By presenting long-range context parsing and sophisticated problem-solving tasks, MuSR serves as a robust benchmark for assessing the advanced reasoning skills of language models.
MATH Level 5: Rigorous Mathematics Evaluation
MATH Level 5 (Mathematics Aptitude Test of Heuristics, Level 5 subset)
Overview: MATH Level 5 focuses on evaluating mathematical reasoning and problem-solving skills at a high-school competition level.
Key Features: This benchmark includes some of the most challenging problems in algebra, geometry, calculus, number theory, and combinatorics. It is designed to test the advanced mathematical capabilities of large language models, ensuring a rigorous evaluation of their ability to handle complex mathematical tasks.
Benefits: By focusing on the hardest questions, MATH Level 5 provides a thorough assessment of a model's mathematical prowess, making it a valuable tool for understanding and improving their problem-solving abilities.
IFEval: Instruction Following Evaluation
IFEval (Instruction Following Evaluation)
Overview: IFEval tests a model's ability to follow explicit instructions accurately.
Key Features: This benchmark uses rigorous metrics to evaluate how well large language models can adhere to natural language instructions. It includes 500 prompts with verifiable instructions such as "write in more than 400 words" or "mention the keyword AI at least 3 times." The focus is on the model's precision and compliance in generating responses that meet specific criteria.
Benefits: IFEval helps gauge the effectiveness of models in following detailed instructions, providing insights into their practical usability and reliability in real-world applications.
BBH: Challenging Tasks in Reasoning and Knowledge
BBH (BIG-Bench Hard)
Overview: BBH is designed to test advanced reasoning and problem-solving skills.
Key Features: This subset of the BIG-Bench dataset includes 23 challenging tasks that require sophisticated reasoning abilities. These tasks cover areas such as multistep arithmetic, algorithmic reasoning, and language understanding. They were selected specifically because they are beyond the capabilities of current language models without advanced techniques like Chain-of-Thought (CoT) prompting.
Benefits: BBH provides a rigorous assessment of a model's high-level reasoning skills, making it an essential benchmark for evaluating the limits of current AI capabilities.
Scoring: The leaderboard now uses normalized scores ranging from a random baseline (0 points) to the maximal possible score (100 points). This new scoring method ensures a fairer comparison across different benchmarks, preventing any single benchmark from disproportionately influencing the final ranking.
Just a reminder: selecting the ideal model for business tasks can be challenging, but you can always rely on LLM Explorer. On LLM Explorer, users can utilize detailed filters to efficiently narrow their search based on model size, performance score, VRAM requirements, availability of quantized versions, and commercial usability, ensuring a match with specific business needs.









