LLM Leaderboards: Insights on AI Model Performance
12/05/2024 14:02:42
LLM leaderboards test language models by putting them through standardized benchmarks backed by detailed methods and large databases. They tackle a range of tasks such as text generation, translation, summarization, and understanding, using challenges like question answering and text completion to see how the models perform. Using consistent methods and precise metrics, these leaderboards offer a fair comparison, clearly showing each model’s strengths and weaknesses in areas like natural language processing and code generation.
There are all sorts of leaderboards out there, each designed to evaluate different aspects of language models. They check everything from general language understanding to how well models handle specialized tasks, emotional intelligence, academic knowledge, multilingual abilities, code generation, and even how they manage controversial content.
This post presents a handpicked collection of leaderboards designed for MLOps and LLMOps, regularly updated based on input from AI experts to ensure accuracy. You can always access the latest version of the list here. We hope this guide assists you in selecting the ideal model for your projects — explore, enjoy the insights, and happy model hunting!
The LMSYS Chatbot Arena Leaderboard
It is one of the most mentioned LLM Leaderboards among AI professionals. The LMSYS Chatbot Arena Leaderboard uses a detailed evaluation system combining human preference votes and the Elo ranking method to assess language models. This crowdsourced platform incorporates various benchmarks like MT-Bench and MMLU and enables users to rank models through interactions with custom prompts and scenarios, mirroring practical use cases.
Users generally like how open and fair the leaderboard is, as it allows everyone to thoroughly assess the models. However, there are worries that the system might prefer models that give the most agreeable answers instead of the most accurate ones. This could twist the results and not truly show what the models can do. Since it relies on human judgment, people’s different standards and preferences could make the evaluations less objective.
Despite these issues, the LMSYS Chatbot Arena is appreciated for promoting competitive development and providing a place for comparative analysis. If its credibility and methods were further improved, it could become even more valuable and accepted in the AI community.
Trustbit LLM Benchmark
The Trustbit LLM Benchmark offers a detailed look at how LLMs perform, especially in digital product development. This tool is great for spotting differences between proprietary cloud models and more flexible open-source options, pointing out which ones work well on local systems.
Trustbits’ monthly LLM Leaderboards are essential tools for identifying the top LLMs suited for digital product development. Each month, based on real benchmark data from their software products, Trustbits re-evaluates the performance of various models in tackling specific challenges. They assess each model’s capabilities across distinct categories, including document processing, CRM integration, external integration, marketing support, and code generation.

EQ-Bench: Emotional Intelligence
EQ-Bench, developed by Samuel J. Paech, is a benchmark that assesses emotional intelligence in language models, focusing on their ability to understand complex emotions and social interactions within dialogues. It utilizes 171 English-language questions to measure how accurately models can predict emotional intensities.
The latest version, EQ-Bench v2, features an improved scoring system designed to better differentiate between model performances and minimize variance from perturbations.
EQ-Bench is praised for its role in advancing language model development, offering critical feedback that aids developers in refining their models. While it is invaluable for initial assessments across various tasks, it may not be perfectly suited for all evaluations, such as creative writing, which underscores the need for more specialized benchmarks.
For business applications, it’s crucial to align the benchmark’s focus — whether on emotional intelligence or general reasoning — with the project’s specific goals. Combining EQ-Bench with other benchmarks can provide a more comprehensive evaluation of a model’s capabilities.
OpenCompass: CompassRank
OpenCompass 2.0 is a benchmarking platform that evaluates large language models across multiple domains using both open-source and proprietary benchmarks. The platform is structured into three core components:
- CompassKit provides tools for evaluation.
- CompassHub is a community-driven repository that offers a wide range of benchmarks.
- CompassRank serves as the leaderboard, ranking models based on their performance.
The evaluation process in OpenCompass 2.0 utilizes multiple closed-source datasets to calculate scores, which include:
- Overall Average: the average score of a model across all datasets.
- Proficiency Score: the average score of a model across datasets that assess specific skills.
In terms of feedback from the AI community, OpenCompass is generally seen as a handy tool for comparing different models. However, you’ll likely hear some rumblings about the integrity of the rankings. Practitioners are pushing for greater transparency in the benchmarking process to make sure that top scores truly reflect a model’s capabilities and aren’t just the result of dataset manipulation.
HuggingFace Open LLM Leaderboard
Now let’s check out the welcoming arms of the Hugging Face Open LLM Leaderboard, a celebrated platform always ready to embrace a new language model 🤗. This comprehensive platform evaluates and ranks open large language models and chatbots by running them through various benchmarks from the Eleuther AI LM Evaluation Harness. This unified framework assesses the effectiveness of generative language models across a spectrum of capabilities like knowledge, reasoning, and mathematical problem-solving. Detailed performance data for each model is available in the Open LLM Leaderboard Results repository, maintained by the Open LLM Leaderboard Hub organization.
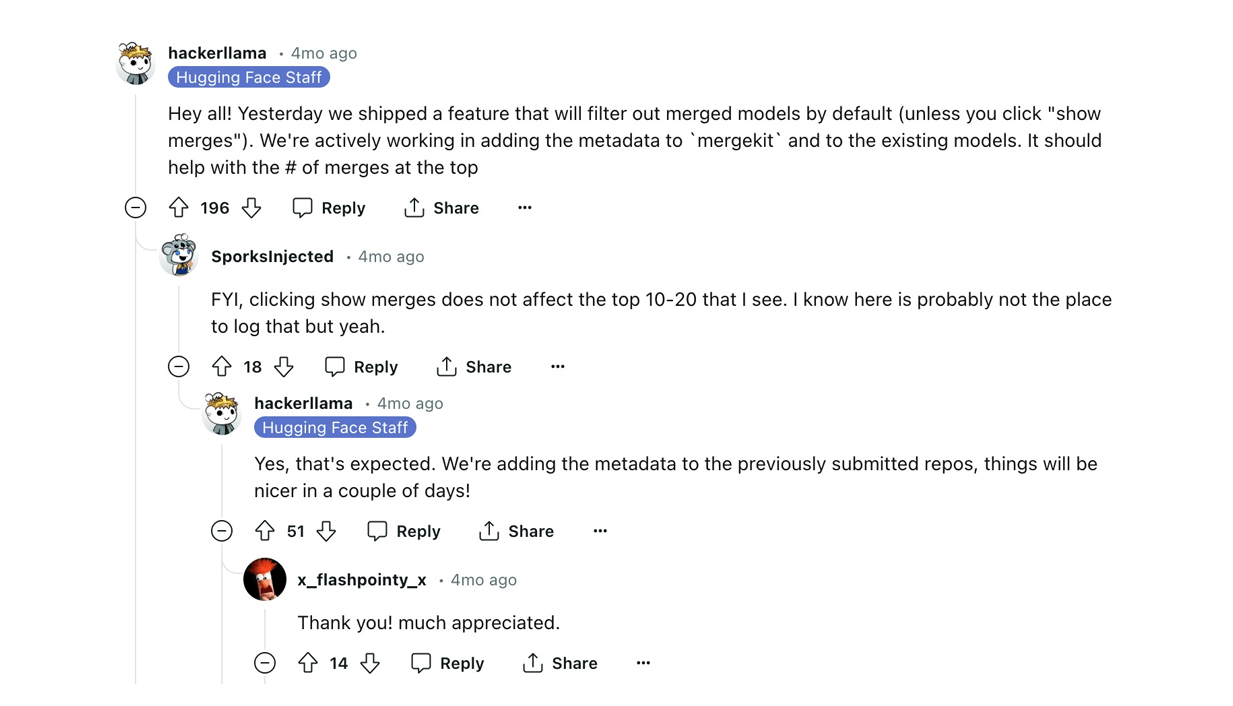
The leaderboard once struggled with merged models topping the ranks, leading to concerns among users about the accuracy of the rankings. In response to feedback that these models might be manipulating the system, Hugging Face introduced a feature to filter out merged models by default, though users can choose to view them if they wish. This adjustment has been positively received, enhancing the platform’s fairness and helping users more easily identify models that truly perform well according to their metrics.
Berkeley Function-Calling Leaderboard
The Berkeley Function-Calling Leaderboard (BFCL) tests LLMs on their ability to process function calls, analyze syntax trees, and execute functions accurately across various scenarios. It features an interactive “wagon wheel” tool for comparing models in nine categories.
The BFCL dataset covers diverse fields like Mathematics-Algebra, Sports-Soccer, and Finance-Mortgage, providing deep insights into model performance. Evaluations are divided into Simple, Multiple, and Parallel Function tests. Simple Function assesses single evaluations, Multiple Function tests the selection of the correct function from options based on context, and Parallel Function involves managing several function calls simultaneously.
This leaderboard aids the integration of LLMs into various software platforms like Langchain, Llama Index, AutoGPT, and Voyager, helping to enhance how these models interact with code. It provides detailed comparative analyses on important metrics such as cost and latency for models including GPT-4.
Users value the BFCL for its sharp focus on function-calling capabilities, noting the breadth of its dataset and recent updates that have added more models and a summary table, making it a practical resource for those keen to enhance their understanding of how language models work with code.
The CanAiCode Leaderboard
The CanAiCode leaderboard, part of the broader CanAiCode test suite, acts as a practical testing ground for small text-to-code LLMs. It’s like a self-evaluation for AI coders, assessing how well these models can turn text inputs into code. Linked to the CanAiCode project, this leaderboard helps evaluate AI models’ abilities to understand and generate code snippets from textual descriptions.
AI professionals value the visibility this leaderboard provides, as it makes it easier to spot and compare various coding models. However, its relevance in real-world applications sometimes falls under scrutiny. Just because a model ranks highly doesn’t necessarily mean it will perform well in actual coding tasks, which can make the leaderboard less reliable for those looking to tackle serious coding projects. There’s ongoing discussion and room for improvement in ensuring the rankings reflect true coding proficiency.
Open Multilingual LLM Evaluation Leaderboard
This leaderboard tracks and highlights the performance of LLMs in a broad array of languages, particularly focusing on non-English ones to broaden LLM benefits to more users globally. It currently evaluates models in 29 languages, including Arabic, Armenian, Basque, Bengali, Catalan, Chinese, Croatian, Danish, Dutch, French, German, Gujarati, Hindi, Hungarian, Indonesian, Italian, Kannada, Malayalam, Marathi, Nepali, Portuguese, Romanian, Russian, Serbian, Slovak, Spanish, Swedish, Tamil, Telugu, Ukrainian, and Vietnamese. Plans are in place to expand this list further.
The platform supports both multilingual and single-language LLMs, assessing them across four benchmarks: AI2 Reasoning Challenge, HellaSwag, MMLU, and TruthfulQA. Translations for these tests are provided by ChatGPT (gpt-3.5-turbo) to ensure all languages are thoroughly included.
Massive Text Embedding Benchmark (MTEB) Leaderboard
The MTEB Leaderboard is a clear resource for evaluating text embedding models across 56 datasets and 8 different tasks. It highlights performance results for over 2000 tests and supports up to 112 languages. This tool is pivotal for those seeking the most effective embedding model for various tasks, considering that the quality of text embeddings significantly depends on the chosen model.
Models on the MTEB leaderboard are assessed based on classification tasks, accuracy, F1 scores, and other metrics, providing a broad comparison of models by English MTEB scores, processing speed, and embedding size. The related Github repository offers all necessary codes for benchmarking and submitting models to the leaderboard.
Users appreciate the leaderboard as a comparative tool for selecting appropriate models for specific applications, often pointing out the tight competition among top-ranked models. They suggest that while the leaderboard is a helpful starting point, direct testing on relevant tasks and data is crucial for confirming a model’s effectiveness in real-world applications. This ensures that the chosen model aligns well with practical needs rather than just theoretical performance. Thus, combining insights from the MTEB with hands-on testing is recommended for a thorough evaluation before deploying embedding models in business settings.
AlpacaEval Leaderboard
The AlpacaEval Leaderboard offers a quick and effective way to evaluate instruction-following language models. It operates on the AlpacaFarm evaluation set, which tests how well models follow general user instructions. The platform compares model-generated responses with GPT -4-based auto-annotated reference responses to calculate win rates, which are then used to rank the models.
The AlpacaEval leaderboard ranks models based on their win rates — how often a model’s output is preferred over the reference outputs. This setup provides a straightforward metric for comparing model performance.
Users appreciate the leaderboard for its ability to quickly compare language models, though some caution is advised. There’s a general consensus that AlpacaEval tends to favor models that closely mimic GPT-4, which might not always equate to broader practical utility. This has led to concerns that high scores might reflect GPT-4 similarity rather than genuine versatility across diverse real-world applications.
Despite potential limitations, the leaderboard is valued for giving a comparative snapshot of model performance, useful for initial assessments, or as part of a broader evaluation process. However, users recommend supplementing leaderboard results with additional metrics and tests tailored to specific real-world tasks to ensure a comprehensive evaluation of a model’s true effectiveness.
Uncensored General Intelligence Leaderboard (UGI)
The Uncensored General Intelligence Leaderboard ranks language models based on their handling of sensitive or uncensored topics, offering an essential reference for those in the industry and research community seeking models adept at managing controversial content. This leaderboard emerges in response to a demand for models that can navigate such topics without censorship, providing a clear and unbiased assessment.
The creator’s approach to maintaining the leaderboard’s integrity involves keeping the evaluation questions confidential to prevent bias and ensure fairness. This method allows for an honest comparison of models ranging in size from 1B to 155B, ensuring they meet ethical standards.
The creator of the leaderboard is highly accessible and responsive. As highlighted by the maker, submissions can be made easily through a simple message or by sending an email directly, ensuring that your models are promptly reviewed and added to the leaderboard.
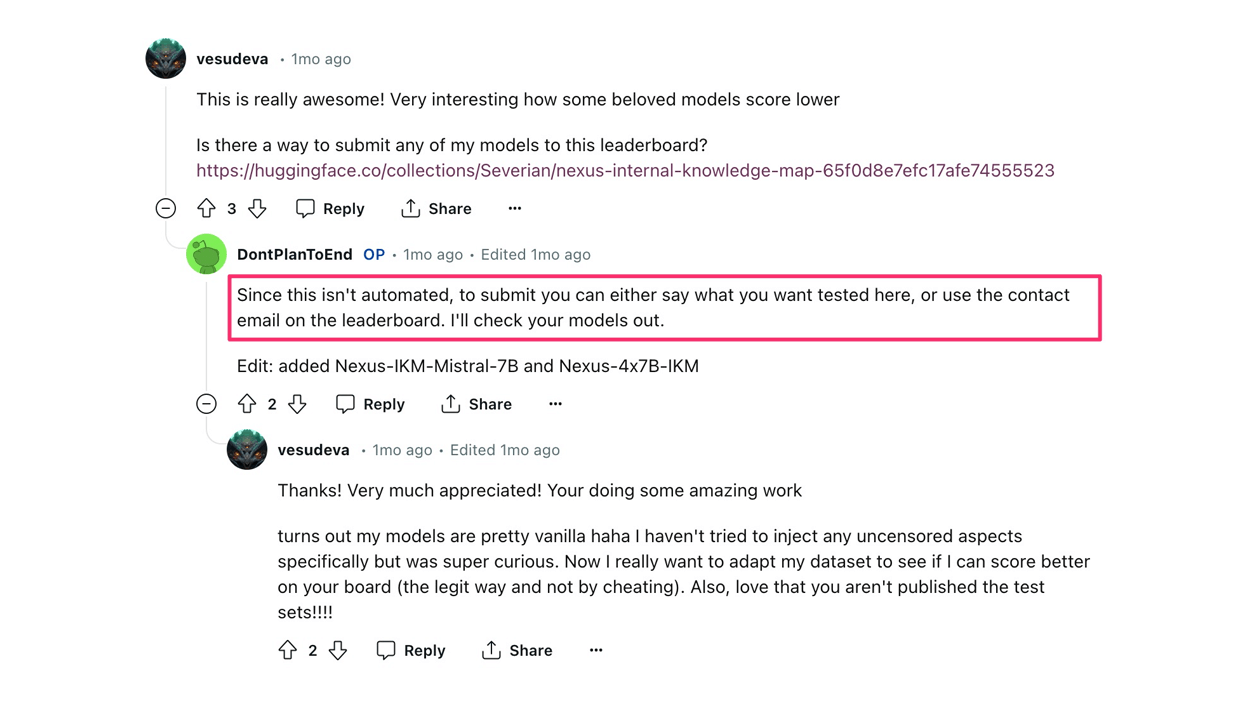
User feedback underscores the utility of the UGI Leaderboard, noting its role in streamlining the search for competent, uncensored LLMs and enhancing efficiency. The community values the leaderboard as a practical tool for easy access and thorough evaluation of language models, confirming its importance in fostering innovation and competition in the field of natural language processing.
Closing Thoughts
While leaderboards like these are invaluable for measuring the effectiveness of LLMs, they’re just the tip of the iceberg. The AI community holds them in high regard not only for setting benchmarks and spurring competition but also for emphasizing the importance of supplementing these insights with hands-on testing for a comprehensive evaluation. The proactive efforts of leaderboard creators to address user feedback and improve system integrity play a pivotal role in keeping them relevant and useful. After all, navigating the bustling world of LLMs without them might just leave us all a bit lost!









