Mistral NeMo 12B: Technical Overview and Initial User Feedback
22/07/2024 16:57:22
To begin with, AI professionals are really excited to see Mistral's ability to develop and release high-quality language models rapidly. The AI community is particularly glad to see more competition in the space of small language models that can run efficiently on consumer-grade GPUs, like the Mistral NeMo 12B model.
A brief overview of the model:
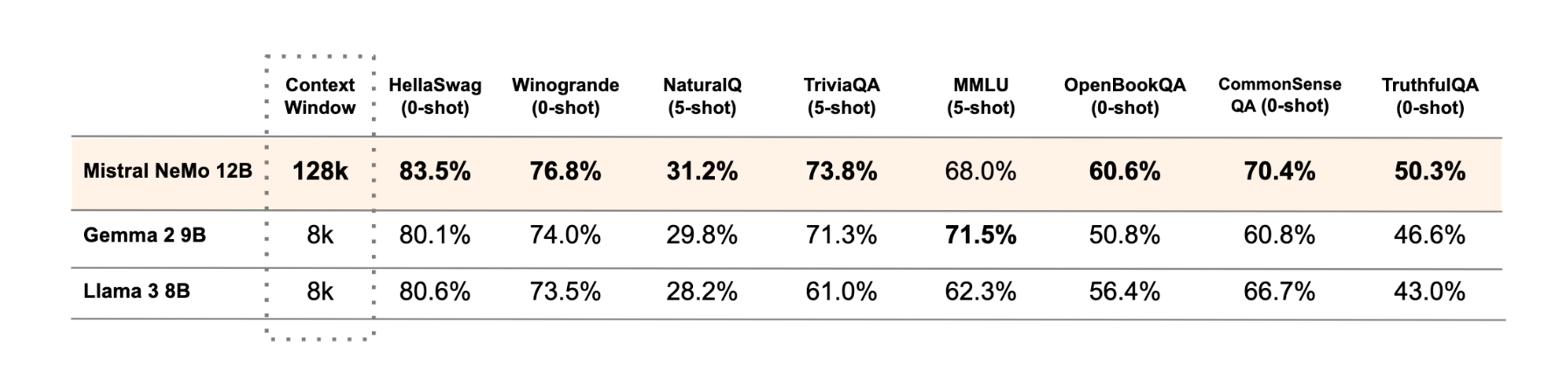
Mistral NeMo is a 12B parameter model with a context window of up to 128k tokens, built on a standard architecture in collaboration with NVIDIA. Released under the Apache 2.0 license, Mistral NeMo is designed to be a drop-in replacement for systems using the previous Mistral 7B model. It comes in two versions - a pre-trained base model and an instruction-tuned model. The model is designed for global, multilingual applications, with particular strength in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. Mistral NeMo uses a new tokenizer called Tekken, based on Tiktoken, which was trained on over 100 languages. Tekken compresses natural language text and source code more efficiently than the SentencePiece tokenizer used in previous Mistral models.
Mistral NeMo underwent an advanced fine-tuning and alignment phase. Compared to Mistral 7B, it demonstrates improved performance in following precise instructions, reasoning, handling multi-turn conversations, and generating code.
Now, let's dive into the first impressions and feedback!
Mistral NeMo's quantization awareness, enabling FP8 inference without performance loss, has been well-received, particularly by those working with quantized models 🐭.
AI professionals were impressed by Mistral NeMo's rare ability to maintain coherence at very large context lengths. The model demonstrates coherence when generating text with a 128K token context and, amazingly, retains some coherence even at 235K tokens despite its relatively small 24GB memory footprint. However, pushing the context too far leads to a significant drop in output quality, necessitating further experimentation to find the optimal balance.
When run on the optimized ExLLaMA V2 platform, the instruction-tuned model exhibited notably uncensored output. This characteristic is advantageous for applications requiring more flexible and unrestricted language generation, including creative writing, roleplaying, and specialized tasks. The model's proficiency in roleplaying scenarios has been particularly highlighted, with users praising its ability to maintain character and context over extended interactions.
Tests conducted on NVIDIA RTX 4090 GPUs using the ExLLaMA 2 (EXL2) inference engine with 8-bit precision weights have yielded impressive performance results as well.
Overall, the early consensus on Mistral NeMo 12B is overwhelmingly positive. The model is rapidly gaining favor, especially in communities focused on open-ended, creative applications. Many are eager to further explore and push its capabilities, particularly in scenarios that benefit from its uncensored nature and strong contextual understanding.








