SmolLM2: The Week's Top-Ranked Compact Language Model
02/11/2024 13:55:33
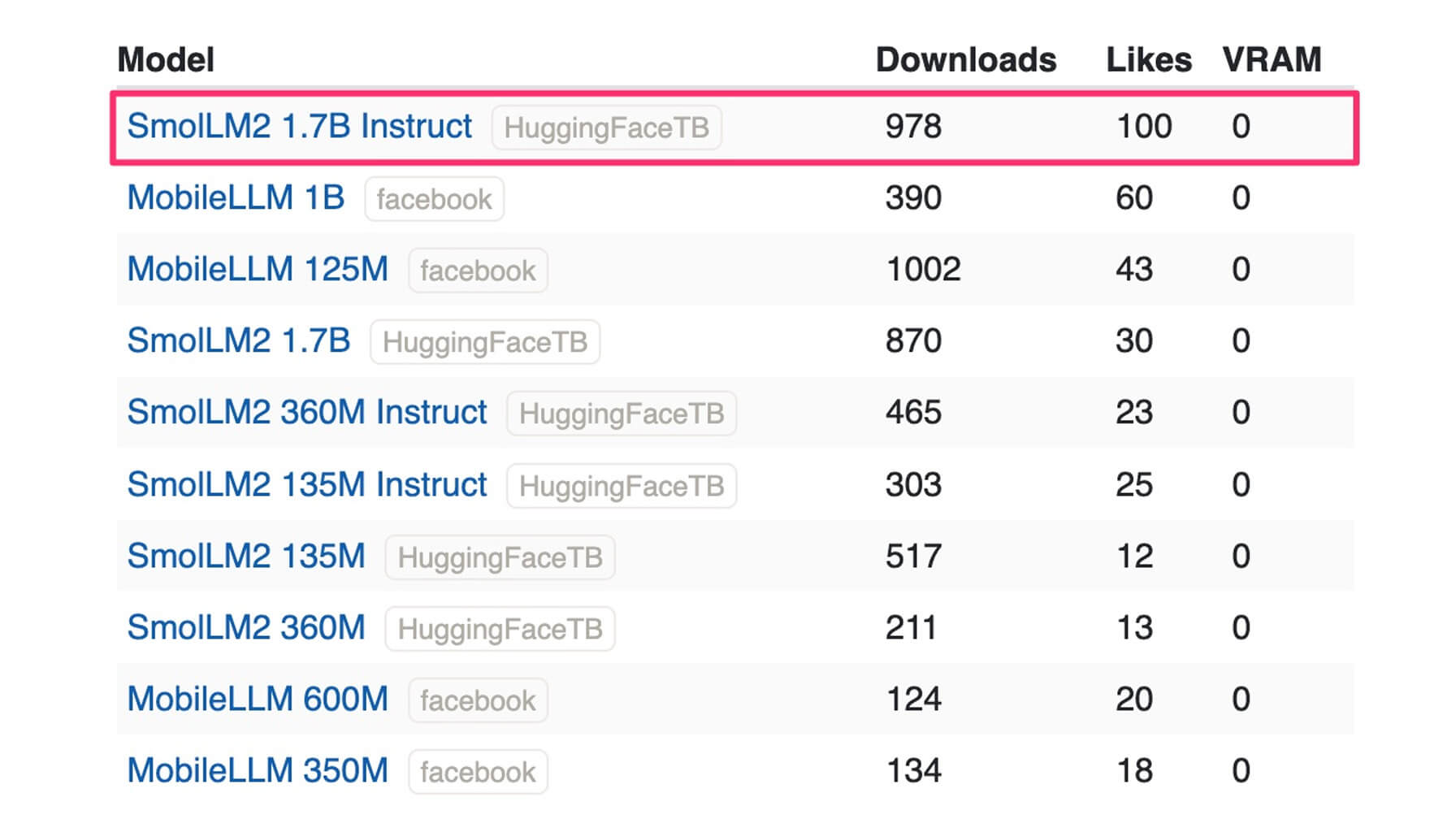
SmolLM2 1.7B Instruct has claimed the top position in our weekly language model rankings, where we evaluate models based on download frequency and user engagement metrics from Hugging Face and LLM Explorer.
The model family has generated significant interest in the AI community, particularly for its impressive performance in a compact form factor. Coming in three variants - 135M, 360M, and 1.7B parameters - users report "shockingly good" performance across the range, with the 1.7B Instruct version drawing special attention from practitioners.
Technical Implementation Details
The development team's training process is particularly noteworthy for those interested in reproduction or fine-tuning. The model was trained on 11 trillion tokens using a diverse dataset combination including FineWeb-Edu, DCLM, and The Stack, along with specialized mathematics and coding datasets. For the instruction-tuned version, the team performed supervised fine-tuning on a ~1M instruction dataset, combining newly curated data with established datasets like OpenHermes2.5, MetaMathQA, Numina-CoT, and self-oss-instruct-sc2. The final step involved Direct Preference Optimization using Ultrafeedback for three epochs.
While the initial training utilized 256 H100 GPUs, the development team confirms that LoRA fine-tuning works effectively on more modest hardware setups - an important consideration for practitioners with limited resources. Multiple users have praised the availability of both base and instruct versions under the Apache 2.0 license, making it particularly accessible for further experimentation and deployment.
Performance and Practical Applications
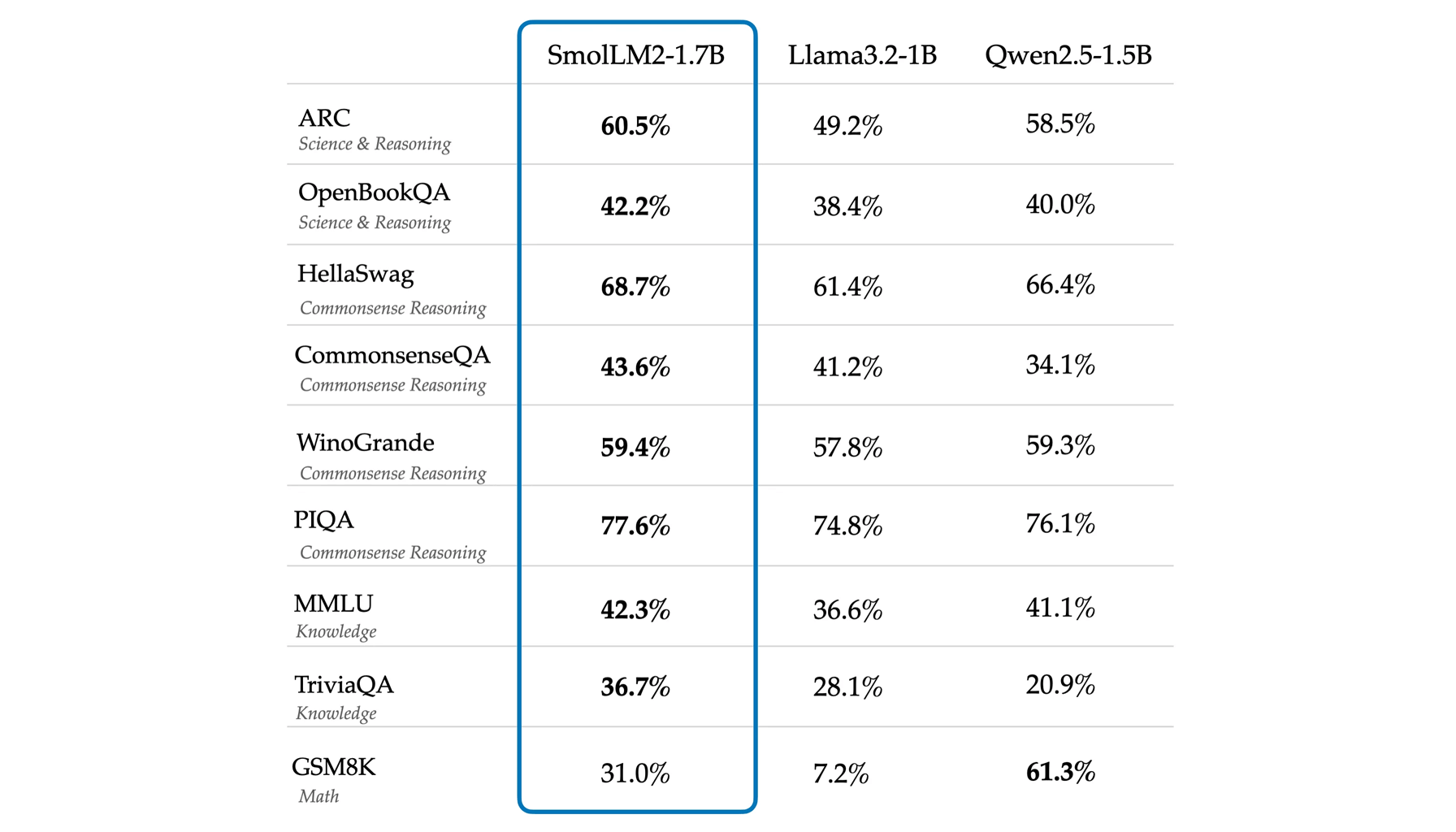
The 1.7B Instruct version has been cited by some experienced users as "probably the best under 2B model" they've tested, with particularly strong coherence and instruction-following capabilities. Users report it performs on par with and sometimes exceeds Qwen2.5 in several benchmarks, making it a notable achievement for its size class.
The 360M variant has emerged as a particular sweet spot in the size/speed/quality balance, with users successfully deploying it on hardware as modest as a Raspberry Pi. The model's compact size makes it suitable for local on-device inference, function calling, and RAG applications - reaching the kind of size that could potentially be shipped in mobile apps rather than requiring OS-level integration. When users discussed potential mobile applications, they referenced apps like Layla and PocketPal as examples of where small language models can be deployed.
Implementation Considerations
When comparing against Gemma 2B (2.61B parameters), users note several distinctions. While Gemma has 53% more parameters, SmolLM2-1.7B offers uncensored operation out of the box and uses the ChatML format for straightforward integration. Users have identified certain characteristics to be aware of during implementation - the model can occasionally get stuck in loops, particularly in creative tasks or uncertain topics. However, these limitations primarily appear in use cases that typically demand larger models, suggesting the importance of aligning the model choice with appropriate applications.
The model's efficient size-to-performance ratio makes it particularly suitable for:
- Local on-device inference
- Function calling applications
- RAG (Retrieval Augmented Generation) implementations
- Mobile app integration
- Edge computing scenarios
For practitioners working with the model, recommended technical considerations include understanding the model's performance characteristics in relation to available computing resources and intended application requirements. The ability to run effectively on consumer-grade hardware, combined with its strong performance in structured tasks, makes it an attractive option for developers looking to implement AI capabilities in resource-constrained environments.