Top-Trending LLMs Over the Last Week (09/09/2024)
09/09/2024 12:27:44
Welcome back to our ongoing series where we spotlight the most trending language models shaping the current AI landscape. We ranked them by how many times they were downloaded and liked, based on information from Hugging Face and LLM Explorer.
This time, let's stop over on the three leading positions of the first autumn week:
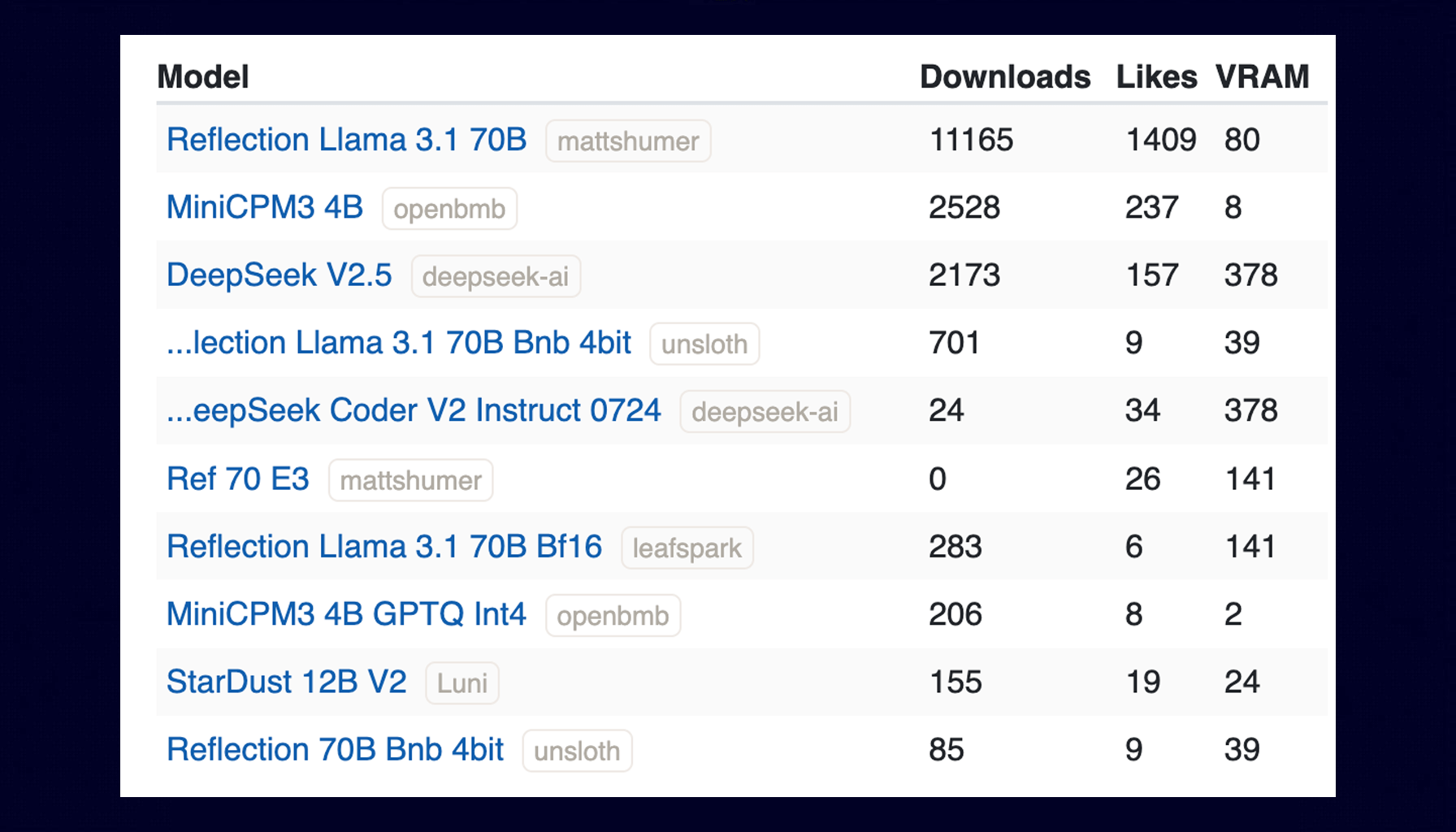
Reflection-Llama-3.1-70B
License: llama3.1
The Reflection Llama-3.1 70B model release unfolded like a detective story 🕵️♀️, marked by controversy and technical issues. On September 5, the creator announced it as the top open-source LLM with impressive metrics. However, the initial model on Hugging Face was non-functional due to incorrect file uploads. A series of problems followed. The model was "fixed" but became a Llama 3 tune instead of Llama 3.1. Independent benchmarks revealed performance significantly below the creator's claims. The model underwent multiple revisions and required retraining. An API was released, but it was later discovered to be a proxy for other models, including Sonnet, GPT-4, and finally Llama 3.1 70B. These events raised significant questions about the model's actual capabilities and the transparency of its development process.
MiniCPM3-4B
License: Apache-2.0 license
MiniCPM3-4B is the 3rd generation of the MiniCPM series, outperforming Phi-3.5-mini-Instruct and GPT-3.5-Turbo-0125, and comparable to many 7B-9B models. It features a 32k context window and supports function calls and code interpretation. Using LLMxMapReduce, it can theoretically handle infinite context without large memory requirements. The model is compatible with Transformers and vLLM libraries for inference. It shows strong performance across various benchmarks, particularly excelling in Chinese language tasks and function calls.
User feedback indicates significant content moderation, particularly for sensitive political topics. The model may provide more information on controversial subjects when queries are framed in an academic context but often gives evasive responses to direct political questions.
DeepSeek-V2.5
License: Commercial use allowed under Model License
DeepSeek-V2.5 is a 21B parameter model combining general and coding abilities, requiring 80GB*8 GPUs for BF16 inference. It supports function calling, JSON output, and FIM completion, and uses an updated chat template. The model shows improved performance across various benchmarks.
User feedback DeepSeek-V2.5 offers coding performance comparable to GPT-4 at a much lower cost. It shows a +5 advantage on ArenaHard but a -3 delta on HumanEval compared to Mistral Large 2. The model may be optimized for LMSys prompts, potentially affecting benchmark results. Notably, it achieves competitive performance with only 21B activated parameters, versus Mistral Large 2's 123B, indicating high efficiency. This model could be particularly suitable for cost-sensitive coding tasks or applications requiring efficient parameter usage.
Stay tuned for the next update, where we'll continue to highlight the top large and small language models making a difference!








