Top-Trending LLMs Over the Last Week. Week #16.
16/04/2024 10:39:11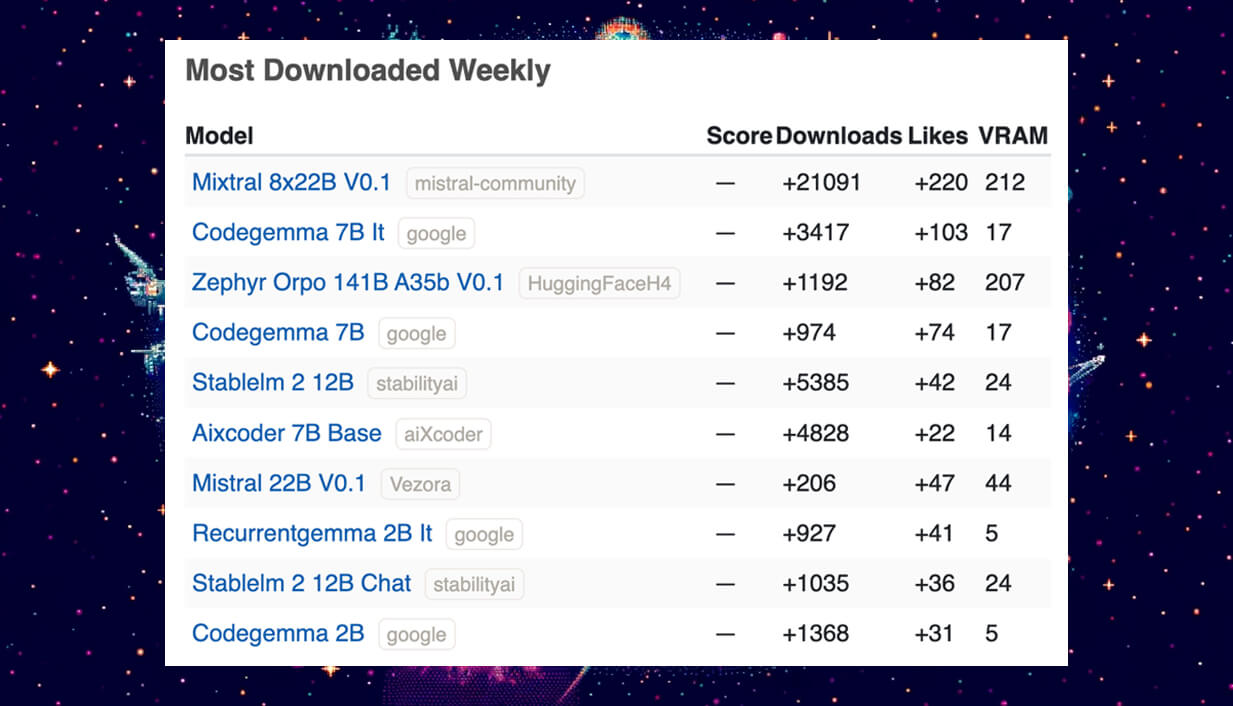
Welcome back to our ongoing series where we spotlight the most trending Large and Small Language Models (LLMs) shaping the current AI landscape. As we enter week #16 of 2024, let’s dive into the roundup of new LLMs that have captured the AI community’s attention. This week, we see a dynamic mix of models that are pushing the boundaries of technology in various aspects of AI, from advanced code generation to enhancing interactive AI experiences.
This week's highlights include the Mixtral 8x22B V0.1 by Mistral-Community, known for its robust performance, and Google's Codegemma 7B and Codegemma 7B IT, which continue to set standards in coding task efficiency. HuggingFaceH4's Zephyr Orpo 141B A35b V0.1 showcases innovative training techniques for efficiency, while Stability AI's Stablelm 2 12B models are celebrated for their reliability in AI interactions. aiXcoder’s 7B Base model remains a favorite for its ease of integration and code comprehension. New entries like Vezora's Mistral 22B V0.1 and recurrent models from Google highlight the ongoing innovation and specialization in the field, catering to specific needs such as iterative learning and lightweight applications.
Mixtral 8x22B-v0.1 by mistral-community
License: apache-2.0
The Mixtral-8x22B Large Language Model (LLM), a pretrained generative Sparse Mixture of Experts, has been effectively converted into a Transformers-compatible format, thanks to the efforts of @v2ray. This model supports various precision modes including half-precision, which can be optimized further using tools within the HuggingFace ecosystem. It is important to note, however, that Mixtral-8x22B lacks built-in moderation mechanisms, which could be a limitation depending on the application.
User Feedback
Feedback from the AI community, particularly from those involved in MLOps and LLMOps, is predominantly positive, emphasizing the model’s robust capabilities in autocomplete tasks and its potential for generating synthetic data to enhance model training. Nevertheless, there are concerns regarding the model’s substantial resource demands, which could pose challenges for deployment on limited or legacy hardware systems. Additionally, while the performance improvements are acknowledged, they are perceived as incremental relative to the model’s increased size and resource consumption.
For optimal utilization, it is recommended that experienced professionals tailor their querying strategies to exploit the model’s strengths, especially in tasks requiring complex autocomplete functions. While Mixtral 8x22B is a significant advancement in LLM technology, its full potential can only be realized with a comprehensive understanding of its operational demands and a robust hardware infrastructure. Engaging with ongoing community feedback and continuous model updates is also advised to leverage advancements and integrate new capabilities effectively.
Codegemma 7b It by Google
License: gemma
The CodeGemma LLM models by Google are specialized for coding tasks such as code completion and generation, available on Hugging Face under specific licensing terms. These models range from 2 billion to 7 billion parameters and are designed to cater to various computational needs and project requirements. However, users have raised concerns regarding the performance of smaller models, their resource intensity, and the complexity of setup.
The Gemma Terms of Use enforce strict guidelines on usage, modification, and distribution. Users must mark all modifications, ensure third parties receive the terms, and adhere to legal compliance. The terms also highlight Google’s right to terminate for breaches, include disclaimers of warranty, and limit liability, making users fully responsible for the outputs and their use.
Practitioners are advised to experiment with different models to find an optimal balance between performance and resource demands and to engage with the community for updates and optimization strategies tailored to specific requirements.
Zephyr Orpo 141B A35b V0.1 by HuggingFaceH4
License: apache-2.0
The Zephyr 141B-A35B model, from the Zephyr series, incorporates the Odds Ratio Preference Optimization (ORPO) alignment algorithm, enhancing computational efficiency and making it well-suited for multi-turn chat applications. Despite its high performance in chat benchmarks, it lacks training alignment with human preferences, which could result in outputs that don't always adhere to safety guidelines. The model is versatile and accessible for tasks like chat, code, and math, but users should use it with awareness of its limitations regarding potentially unsafe outputs.
For AI practitioners, Zephyr 141B-A35B is a robust tool that offers substantial performance benefits without the heavy computational demands typical of similar models. It is fine-tuned from the Mixtral-8x22B-v0.1 using the specialized argilla/distilabel-capybara-dpo-7k-binarized dataset, suggesting high efficiency and effectiveness. Potential users should note the model’s VRAM requirements and its complex setup needs, which may require advanced hardware and significant expertise in prompt engineering to achieve optimal results.
User Feedback
For potential users of Zephyr 141B, it is recommended to thoroughly test the model across various tasks to assess its effectiveness for your specific needs, due to its mixed performance reviews. Additionally, investing time in learning how to craft effective prompts is essential to maximize output quality. Staying informed about the latest updates from the developers and being ready to adjust your technical approaches are crucial steps to fully harness the capabilities of Zephyr 141B.
Zephyr 141B-A35B promises access and versatility, but realizing its full potential requires a nuanced approach to its deployment and application.
Stablelm 2 12B by stabilityai
The Stable LM 2 12B from Stability AI is a robust decoder-only language model with 12.1 billion parameters, designed to efficiently generate text from a training set of 2 trillion tokens spanning multilingual and coding datasets. It operates on a transformer decoder architecture capable of handling long sequence lengths, making it ideal for developers looking to tailor application-specific fine-tuning. For commercial use, Stability AI requires users to adhere to specific licensing terms available through their membership program.
AI professionals should note that while the model offers a strong foundation for various applications, it necessitates careful adjustment and evaluation to ensure safe and effective use in production environments. The model's potential, combined with the need for strategic fine-tuning, presents a significant opportunity for innovation in language processing tasks.
User Feedback
User feedback on the model, reveals a blend of excitement and hesitation regarding its capabilities. Users appreciate the model's innovative features like function calling for interactive uses and its potential for fine-tuning in languages like German, recognizing the model as a step forward in LLM technology. However, there's enthusiasm about its ability to push technological boundaries with new model architectures.
On the other hand, the model faces criticism for compatibility issues with existing tools, necessitating updates for integration, and its structured response format which may not suit all interaction types. Concerns also arise from its licensing restrictions, limiting its commercial application, and the need for significant local adjustments to optimize language performance. The community's mixed reactions underscore a cautious optimism, balanced against these operational challenges.
Aixcoder-7b-base by aiXcoder
The aiXcoder-7B Code Large Language Model is recognized for its effective performance in code-related tasks across multiple programming languages, having been fine-tuned on 1.2 trillion unique tokens. This training enables it to outperform competitors like CodeLlama 34B and StarCoder2 15B in multilingual code generation benchmarks. Currently optimized for tasks like code completion, the aiXcoder 7B is set for updates that will expand its utility into more complex functions such as test case generation and debugging.
For AI professionals and developers, it is important to understand the model's licensing restrictions. Available for non-commercial use under academic terms, the commercial application requires a separate license, obtainable via support@aiXcoder.com.
User Feedback
The model’s licensing terms restrict commercial use and include clauses regarding national security and public interest, which have raised concerns within the community. These factors, along with the model's compatibility with most existing libraries, position it as both a promising and challenging option for integration into various development environments.
As aiXcoder 7B continues to develop, AI practitioners should weigh its technical capabilities against the legal and ethical considerations of its use to ensure compliance with legal frameworks and operational requirements.
Mistral 22B V0.1 by Vezora
License: apache-2.0
The Mistral-22b-V.01, released on April 11 by Nicolas Mejia-Petit, is a 22 billion parameter-dense model crafted from the distillation of knowledge from multiple experts into a single model, marking a pioneering conversion from a MOE to a dense format. Although it's an experimental model with modest training on 1,000 Q/A and Python examples, it shows strong math capabilities and serves as a preliminary version before the enhanced V.2, expected to improve multi-turn conversation and coding abilities. The release aims to provide the community with official access to innovative modeling techniques, acknowledging the contributions of various AI and software development experts in enhancing the model's training efficiency and capabilities.
User Feedback
User feedback on Vezora's Mixtral 22B Model highlights its function calling and fine-tuning capabilities, particularly for enhancing performance in specific languages like German, alongside the introduction of innovative architectures that advance LLM technology. However, users report compatibility issues with existing tools and the need for extensive fine-tuning, alongside concerns about its structured response format and restrictive non-commercial licensing, which limits wider application. Overall, the community response is mixed: there is excitement about its potential, tempered by caution due to integration challenges and licensing implications, with a keen interest in how upcoming variants might compare to models like Mistral 7B.
Recurrentgemma 2B It by Google
License: gemma
The RecurrentGemma model on Hugging Face is accessible upon agreeing to Google's usage terms, featuring both a 2B instruction-tuned version for specific tasks and a 2B base model for broader applications. This model integrates easily with existing libraries, allowing users to leverage its capabilities for diverse text generation tasks, including running on multiple GPU setups and utilizing conversational templates for enhanced user interaction. Developed with a novel recurrent architecture by Google, RecurrentGemma is designed for efficiency, requiring less memory and achieving faster inference on long sequences compared to other models of its size.
User Feedback
The model has garnered attention for its function-calling capabilities, enhancing its utility for dynamic applications and its notable fine-tuning success, particularly in processing the German language. This adaptability to specific linguistic requirements alongside the introduction of innovative architectures has been well-received, as these features potentially push the operational boundaries of large language models, offering new uses and efficiencies.
On the other hand, the model faces several challenges that affect its broader acceptance. Initial compatibility issues with existing tools and frameworks have hindered swift adoption, and there's a significant need for extensive fine-tuning to optimize performance across different languages. Additionally, the structured nature of its responses might not suit all interaction types, and updates in supporting libraries are necessary due to its unique architecture. Moreover, the restrictive non-commercial licensing has been a point of contention, particularly among users looking to leverage the model for commercial purposes, highlighting the complex landscape of deploying such advanced AI tools in diverse development environments.
Stablelm 2 12B Chat by stabilityai
Stable LM 2 12B Chat is a 12 billion parameter language model specifically tuned for conversational tasks, trained on a combination of publicly available and synthetic datasets using Direct Preference Optimization (DPO). This model, designed to handle chat-like interactions, incorporates a chat format that utilizes AutoTokenizer's apply_chat_template method, facilitating dynamic and contextually aware conversations. Developed by Stability AI, the model supports function calling and is available under a non-commercial research community license, with potential commercial use requiring direct contact with Stability AI for licensing arrangements.
Stay tuned for next week's update, where we'll continue to highlight the top Large Language Models making a difference!
← Previous Week's Top LLMs Next Week's Top LLMs →








